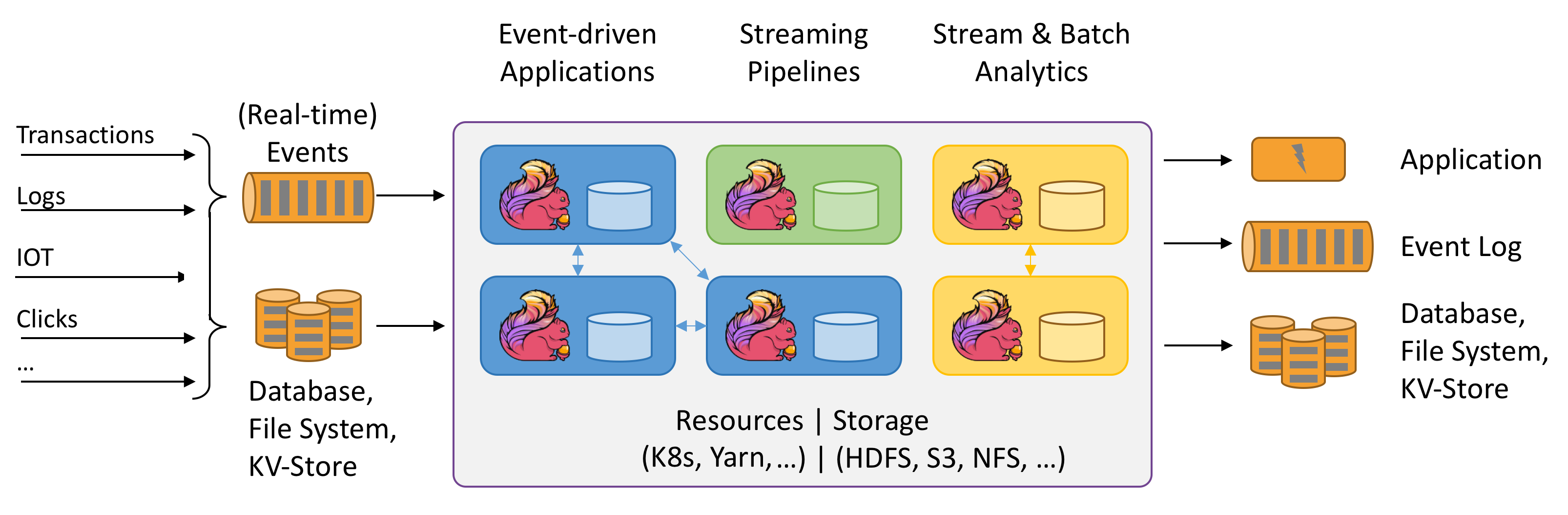
Flink基础学习
flink
flink安装
自从微软在 windows 10 内集成了 wsl ,对于开发人员来说简直不要太方便了,尤其是听说下个版本的 wsl2 还支持 Docker。大数据环境基本对 windows 的支持很差,但是有了 wsl 就完全不一样了。
如何开启和安装 wsl 就不多介绍了,可以 百度/Google 一下。我安装的是 ubuntu 16.04 LTS 。
flink 的安装还是比较简单的,环境基本安装好 jdk 即可。
JDK 安装
我这里安装的是 Open JDK ,只需要一行命令即可。
sudo apt-get install openjdk-8-jdk如果安装出错,先更新一下
sudo apt-get update下载安装完成后,通过 java 和 javac 看看是否安装成功。
flink 安装
flink的安装就更加简单了,到 **flink 官方/中文网 ** 找到下载页面,选择你要的版本(我选择的是 Apache Flink 1.7.2 with Hadoop® 2.8 for Scala 2.12),点击下载之后官方会帮你选择一个镜像链接。然后下载即可。
通过 wget 命令下载
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.7.2/flink-1.7.2-bin-hadoop28-scala_2.12.tgz等待下载完成即可。
下载完成之后,解压压缩包,完成项目。
tar -zxf flink-1.7.2-bin-hadoop28-scala_2.12.tgz打开解压后的文件,我们在 bin 目录下找到 start-cluster.sh , 启动该脚本即可运行。
./start-cluster.sh运行该脚本,启动 flink 。

如图,启动成功。
此时在 windows 上打开浏览器 http://localhost:8081 可以看到 flink 控制台。
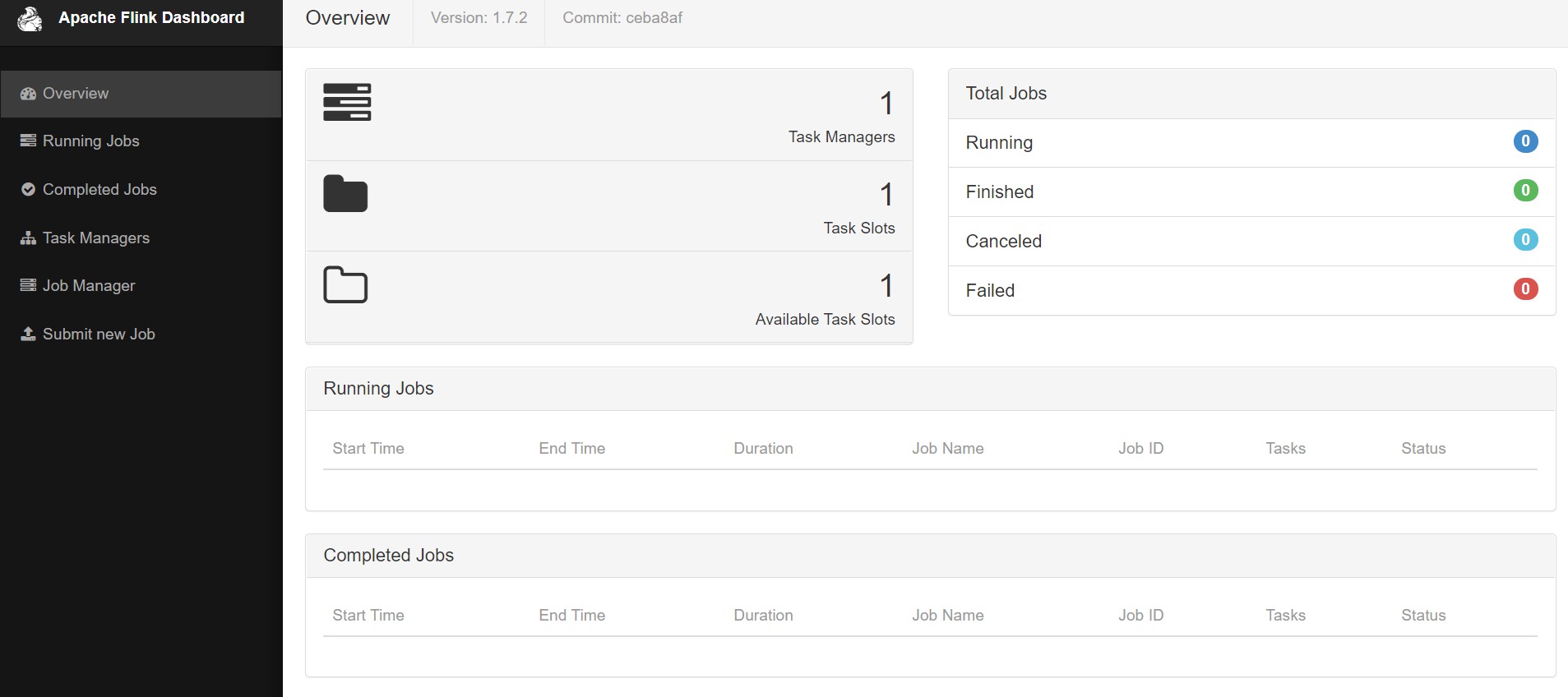
此时的 flink 项目已经启动成功。已经完成了安装工作。
编写flink代码
通过idea创建 maven/gradle 项目,导入必要的包,下面为 maven 依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>log4j</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>注意部分依赖使用的范围 scope 是 provided,该属性为在项目打包是不会打包,但是本地运行项目时候需要,所以在本地调试的时候要将该属性注释掉,否者或报错。
下面是 Scala 版本的 wordCount
package top.young.wordcount
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
object WordCount {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = List("hi", "how are you", "hi")
val ds = env.fromCollection(data)
val counts = ds.flatMap(
_.toLowerCase.split("\\W+").filter(_.nonEmpty)).map {
(_, 1)
}.groupBy(0).sum(1)
counts.print()
}
}运行会有执行结果
(are,1)
(you,1)
(hi,2)
(how,1)确认项目可以正确运行后可以进行打包。执行maven的 package 命令,会在target目录中找到我们打包好的jar
运行 Flink 代码
打开我们的控制台 http://localhost:8081 ,选择 submit new job ,点击 Add New 将我们的jar包上传上去,并且填写相关信息,在Entry Class 地方填写主类的名称 top.young.wordcount.WordCount
项目会启动运行。
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
赞赏