Apriori算法
前言
下文所有内容基本总结于 《数据挖掘概念与技术 第三版》机械工业出版社
最近复习数据挖掘课程,就把复习的几个算法记录一下。
什么是Apriori算法
Apriori算法是 Agrawal 和 R.Srikant 与1994 提出的,为布尔关联规则挖掘频繁项集的原创性算法。Apriori算法使用一宗称为逐层搜索的迭代方法,其中 k 项集用于探索 (k+1) 项。
基本为扫描数据库,累计每个项的计数,并且收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,如此一直找下去,知道不能再找到频繁k项集,找出每个Lk需要一次数据库的完整扫描。
寻找频繁项集
先验性质
为了提高频繁项集逐层产生的效率,一种称为先验性质的重要性质用于压缩搜索空间。
先验性质:频繁项集的所有非空子集也一定是频繁的。
该表是一个事务数据库D。该数据库有9个事务,即|D|=9。假设最小支持度为2
| TID | 商品ID的列表 | TID | 商品ID的列表 |
|---|---|---|---|
| T100 | I1,I2,I5 | T600 | I2,I3 |
| T200 | I2,I4 | T700 | I1,I3 |
| T300 | I2,I3 | T800 | I1,I2,I3,I5 |
| T400 | I1,I2,I4 | T900 | I1,I2,I3 |
| T500 | I1,I3 |
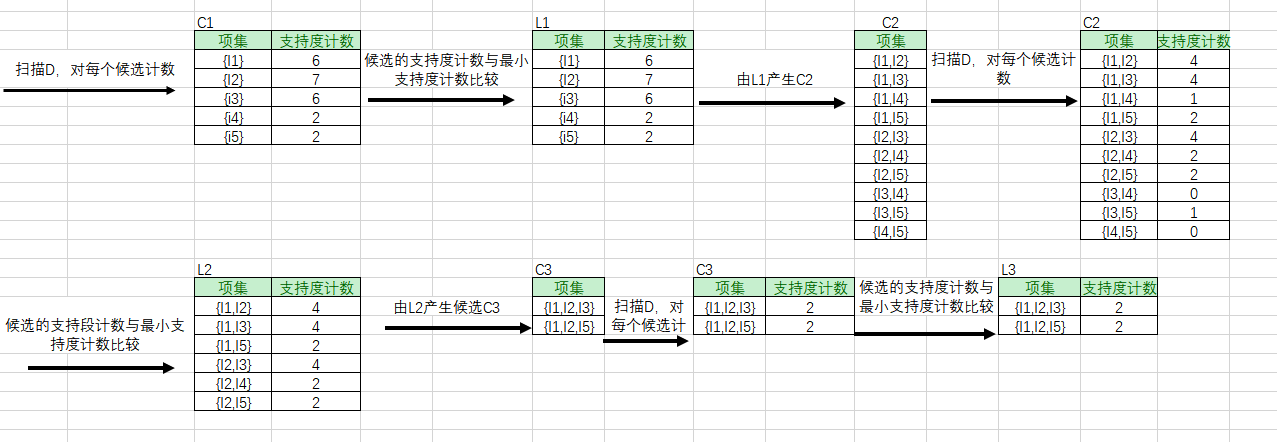
在算法第一次迭代的时候,每个项都是候选1项集的集合C1的成员。算法扫描,统计出每个项出现的次数。
可以确定频繁1项集的集合L1,它由满足最小支持段的候选1项集组成。
为发现频繁2项集的集合L2,算法使用L1 🔗 L1产生候选2项集的集合C2。注意剪枝,没有候选的C2中删除,因为这些候选的每个子集也是频繁的。
扫描D中的事务,累计C2中的每个候选项集的支持技术。
然后确定频繁2项集的集合L2,它由C2中满足最小支持度的候选2项集组成。
…………
重复以上步骤,直到Cn = ∅,此算法终止,找出所有的频繁项集。
由频繁项集产生关联规则
一旦由数据库D中的事务找出频繁项集,就可以直接由它们产生强关联规则。对于置信度,可以用下面的公式计算。
confidence(A =>B) = P(A | B)= support_count(A ∪ B) / support_count(A)
继续使用上面的案例,该数据包含频繁项集 x = {I1,I2,I5},可有X产生哪些关联规则,并且计算{I1,I2},{I1,I5},{I1}置信度
产生的关联规则
{I1,I2},{I1,I5},{I2,I5},{I1},{I2},{I5}
{I1,I2} => I5, confidence = 2 / 4 = 50%
{I1,I5} => I2, confidence = 2 / 2 = 100%
相关内容
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
赞赏