python爬取斗鱼图片
目录
警告
本文最后更新于 2019-04-14,文中内容可能已过时。
介绍
一个简单的 Python 爬虫,用于爬取斗鱼网上的图片。
- 编辑工具:Visual Studio Code
- Python 版本:2.7
- 使用的库:urllib
Visual Studio Code插件
- Code Runner
- Python
- Python for VSCode
- MagicPython
实现思路
首先要打开地址,并且获取该网页的代码。
从代码里获得你要图片。这里我们需要简单的分析一下该网页。
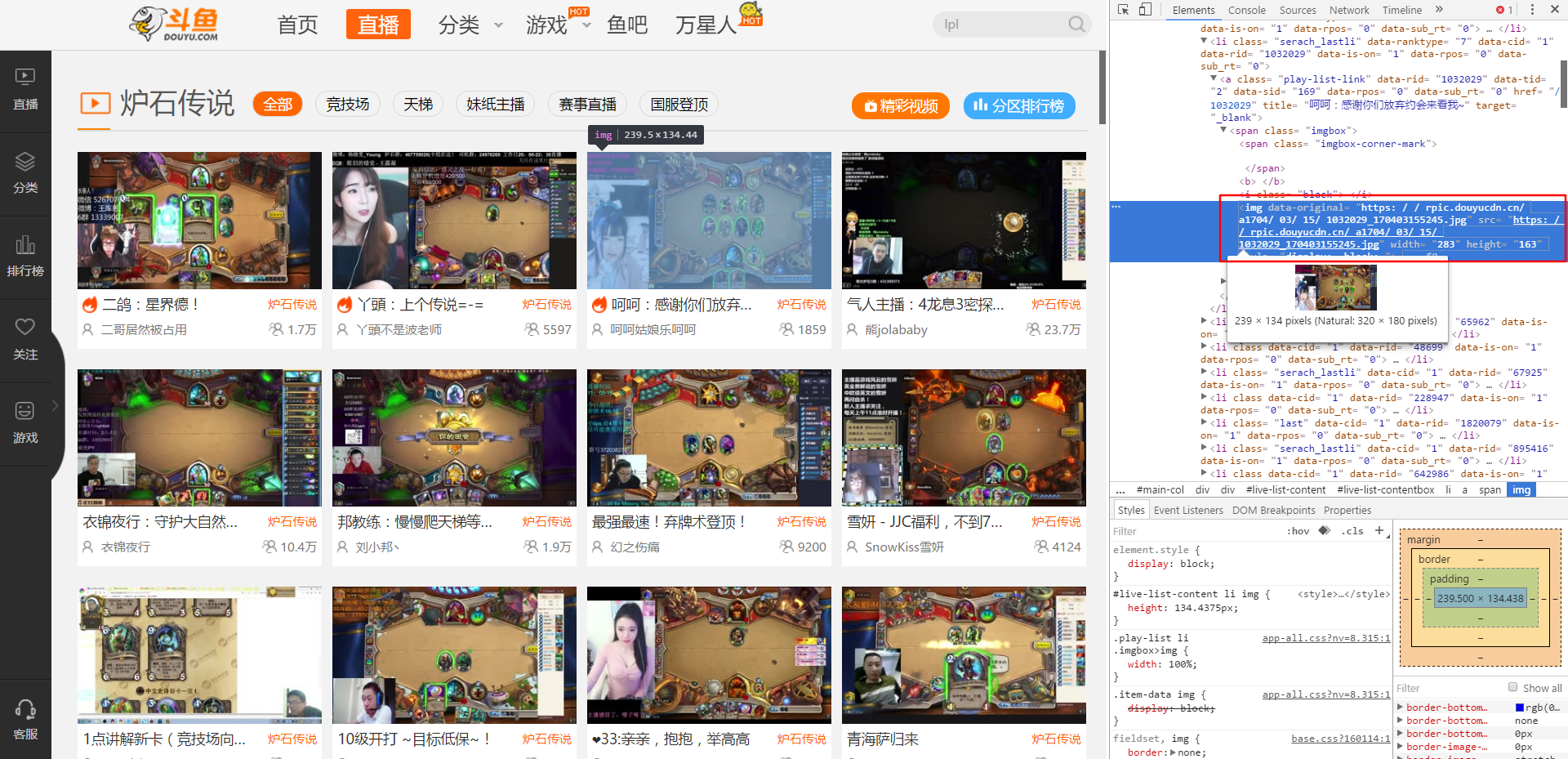
当我们把鼠标移到地址上的时候就会出现该图片,这个就是我们要爬取的图片。
这个图片是在 data-original 后面,我们就需要进行匹配,通过正则表达式很快就可以达到目的。
网页代码片段
<img data-original="https://rpic.douyucdn.cn/a1704/03/15/1032029_170403155245.jpg" src="https://rpic.douyucdn.cn/a1704/03/15/1032029_170403155245.jpg" width="283" height="163" style="display: block;">正则表达式 data-original="(.*?\.(jpg|png))
这样我们就获取到了这个页面上所有的 jpg 和 png 图片。
最后通过 urlretrieve 这个方法把图片保存到你想要放的地方。
代码
# coding:utf8
import urllib
import re
import time
# 通过filename设置路径和名字
response=urllib.urlopen('https://www.douyu.com/directory/game/TVgame')
html=response.read()
print html
imglist=re.findall(r'data-original="(.*?\.(jpg|png))"',html)
print imglist
x=0
for imgurl in imglist:
print ('下载图片 %s'%imgurl[0])
if imgurl[1]=='gif':
urllib.urlretrieve(imgurl[0],filename='G:\PythonCode\pic\%d.gif'%x)
else:
urllib.urlretrieve(imgurl[0],filename='G:\PythonCode\pic\%d.jpg'%x)
x+=1
time.sleep(1)相关内容
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
赞赏