协同过滤算法
前言
在推荐系统中有很多算法,其中一种就是协同过滤算法。
分类
在协同过滤算法中,分为两类,基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。每个类型的适用情况不同。
在上述的两种类型中,基于用户的协同过滤算法是不太常用的,原因如下
- 用户的数量是远远大于物品的数量,计算用户之间的相似度计算量会很大。
- 对于一个新用户很难找到相似度
所以一般是不会使用基于用户的协同过滤,但是并不表示不用,一般用于新闻推送等。
相似度计算
离散图表示
目前有五个用户对商品1和商品2的喜爱程度,分析用户之间的关系。
| 用户 | 商品1 | 商品2 |
|---|---|---|
| 1 | 3.3 | 6.5 |
| 2 | 5.8 | 2.6 |
| 3 | 3.6 | 6.3 |
| 4 | 3.4 | 5.8 |
| 5 | 5.2 | 3.1 |
寻找他们的相似度
通过离散图来进行表示
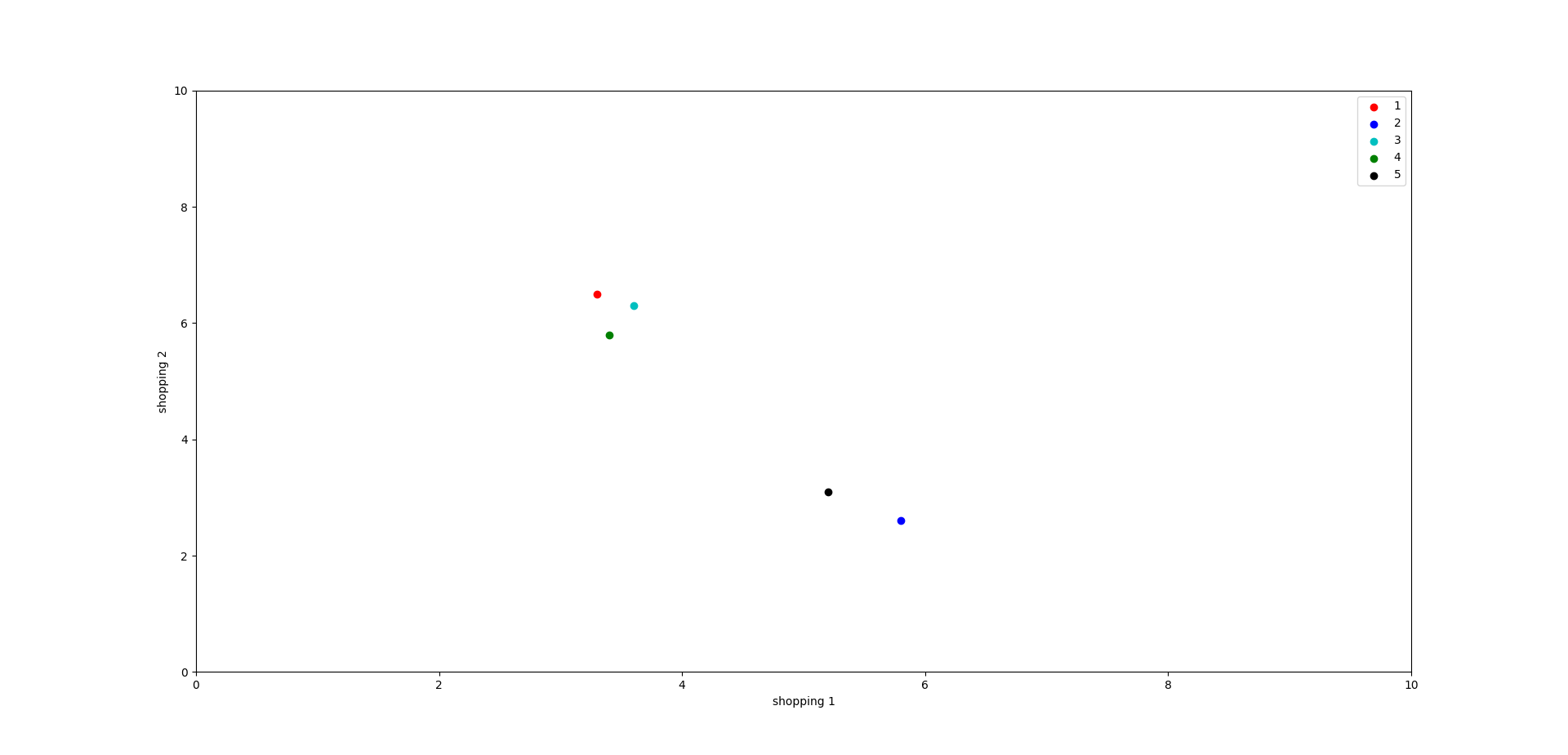
可以看出 用户1 用户3 用户4 之间是存在关系的。
# coding = utf8
import matplotlib.pyplot as plt
import numpy as np
# 散点图分析五个用户之间的相关程度
# x轴为对于商品 1 的喜欢程度
# y轴是对于商品 2 的喜欢程度
# 数据如下
# 商品1 [3.3, 5.8, 3.6, 3.4, 5.2]
# 商品2 [6.5, 2.6, 6.3, 5.8, 3.1]
shop1 = [3.3, 5.8, 3.6, 3.4, 5.2]
shop2 = [6.5, 2.6, 6.3, 5.8, 3.1]
color = ['r', 'b', 'c', 'g', 'y', 'k', 'm', '0xff0012']
for i in range(0, len(shop1)):
plt.scatter(shop1[i], shop2[i], c=color[i])
plt.xlim(0, 10)
plt.ylim(0, 10)
plt.ylabel("shopping 2")
plt.xlabel("shopping 1")
plt.legend('12345')
plt.show()欧几里得距离
欧几里得距离是最常用的距离公式,用于计算两点之间的距离。公式如下:

通过计算两点之间的距离来表示他们之间的相关程度。
我们通过 python 计算 欧几里得距离。
# coding = utf8
# 1 2 3 4 5
shop1 = [3.3, 5.8, 3.6, 3.4, 5.2]
shop2 = [6.5, 2.6, 6.3, 5.8, 3.1]
for i in range(0, len(shop1) - 1):
for j in range(i + 1, len(shop2)):
distance = (shop1[i] - shop1[j]) ** 2 + (shop2[i] - shop2[j]) ** 2
correlation = 1 / (1 + distance) # 将范围缩小至0 ~ 1 之间
if correlation > 0.60: # 根据需求更换相关系数
print("第 {} and {} distance is {}".format(i + 1, j + 1, correlation))计算结果
第 1 和 2 相关系数是 0.04452359750667854
第 1 和 3 相关系数是 0.8849557522123891
第 1 和 4 相关系数是 0.6666666666666665
第 1 和 5 相关系数是 0.061842918985776124
第 2 和 3 相关系数是 0.051203277009728626
第 2 和 4 相关系数是 0.058823529411764705
第 2 和 5 相关系数是 0.6211180124223604
第 3 和 4 相关系数是 0.7751937984496123
第 3 和 5 相关系数是 0.07246376811594203
第 4 和 5 相关系数是 0.08673026886383348
得出结论,基本和离散图相似。
这样就可以根据需求来判断用户之间的相似度。
皮尔逊相关系数
皮尔逊相关系数同样也是计算距离的一种方式
通过相关系数可以计算出他们的相关程度。
适用范围
皮尔逊相关系数是有一定的适用条件。
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于: (1)、两个变量之间是线性关系,都是连续数据。 (2)、两个变量的总体是正态分布,或接近正态的单峰分布。 (3)、两个变量的观测值是成对的,每对观测值之间相互独立。
同样这个算法也是有缺陷的,但数据越少的时候,波动性越大。当数据很少的时候不建议使用。
皮尔逊相关系数公式有四个
公式一:

公式二:

公式三:
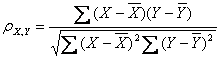
公式四:

相关系数
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
我们通过第四个公式进行计算
简单案例
通过 python 计算出相关系数
# coding=utf8
# 皮尔孙相关系数计算
def PearsonCorrelationSimilarity(vec1, vec2):
value = range(len(vec1))
sum_vec1 = sum([vec1[i] for i in value])
sum_vec2 = sum([vec2[i] for i in value])
square_sum_vec1 = sum([pow(vec1[i], 2) for i in value])
square_sum_vec2 = sum([pow(vec2[i], 2) for i in value])
product = sum([vec1[i] * vec2[i] for i in value])
numerator = product - (sum_vec1 * sum_vec2 / len(vec1))
dominator = ((square_sum_vec1 - pow(sum_vec1, 2) / len(vec1)) * (
square_sum_vec2 - pow(sum_vec2, 2) / len(vec2))) ** 0.5
if dominator == 0:
return 0
result = numerator / (dominator * 1.0)
return result
if __name__ == '__main__':
# 五个用户对五个商品的评价
user1 = [3.3, 5.8, 3.6, 3.4, 5.2]
user2 = [6.5, 2.6, 6.3, 5.8, 3.1]
user3 = [5.5, 3.2, 6.5, 4.7, 4.4]
user4 = [4.4, 6.2, 2.3, 5.1, 3.3]
user5 = [2.1, 5.2, 4.2, 2.2, 4.1]
userlist = [user1, user2, user3, user4, user5]
for i in range(0, len(userlist) - 1):
for j in range(i + 1, len(userlist)):
result = PearsonCorrelationSimilarity(userlist[i], userlist[j])
print "user%d 和 user%d 的相关系数是%f" % (i + 1, j + 1, result)user1 和 user2 的相关系数是0.999774
user1 和 user3 的相关系数是-0.847758
user1 和 user4 的相关系数是-0.841816
user1 和 user5 的相关系数是-0.915237
user2 和 user3 的相关系数是-0.841741
user2 和 user4 的相关系数是-0.835320
user2 和 user5 的相关系数是-0.909975
user3 和 user4 的相关系数是0.998987
user3 和 user5 的相关系数是0.976272
user4 和 user5 的相关系数是0.969782
通过计算出来的结果可以看出来等到的结果
余弦距离
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
公式
一般余弦定理这个公式运用与文本分析。
分别采用下列的文本进行
示例
A:这里距离北京有多远,火车多长时间
B:北京离这里有多远,坐火车多长时间
对A,B进行分词
A:这里/距离/北京/有/多远,火车/多长/时间
B:北京/离/这里/有/多远,坐/火车/多长/时间
列出所有的词
这里 距离 北京 有 多远 火车 多长 时间 离 坐
进行词频统计
A: 这里(1)距离(1)北京(1)有(1)多远(1)火车(1)多长(1)时间(1)离(0)坐(0)
B: 这里(1)距离(0)北京(1)有(1)多远(1)火车(1)多长(1)时间(1)离(1)坐(1)
计算句子的词频向量
A (1,1,1,1,1,1,1,1,0,0)
B (1,0,1,1,1,1,1,1,1,1)
通过余弦定理计算相似度
# coding=utf8
import math
# 余弦定理
def cos(v1, v2):
l = 0.0
for i in range(0, len(v1)):
l += v1[i] * v2[i]
v = 0.0
w = 0.0
for i in range(0, len(v1)):
v += math.pow(v1[i], 2)
w += math.pow(v2[i], 2)
cos = l / (math.sqrt(v) * math.sqrt(w))
return cos
if __name__ == '__main__':
v1 = [1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
v2 = [1, 0, 1, 1, 1, 1, 1, 1, 1, 1]
l = cos(v1, v2)
print l计算出的相似度为:
0.824957911384
说明这两句话基本相等
这是一些基本的相似度计算方法。
相关内容
如果你觉得这篇文章对你有所帮助,欢迎赞赏~
赞赏